
A Google Cloud Search schema is a JSON structure that defines the objects, properties, and options to be used in indexing and querying your data. Your content connector reads data from your repository and, based on your registered schema, structures and indexes the data.
You can create a schema by providing a JSON schema object to the API and then registering it. You must register a schema object for each of your repositories before you can index your data.
This document covers the basics of schema creation. For information on how to tune your schema to improve the search experience, refer to Improve search quality.
Create a schema
Following is a list of steps used to create your Cloud Search schema:
- Identify expected user behavior
- Initialize a data source
- Create a schema
- Complete sample schema
- Register your schema
- Index your data
- Test your schema
- Tune your schema
Identify expected user behavior
Anticipating the types of queries your users make helps direct your strategy for creating your schema.
For example, when issuing queries against a movie database, you might anticipate user's making a query such as "Show me all movies starring Robert Redford." Your schema, therefore, must support queries results based on "all movies with a specific actor."
To define your schema to reflect your user's behavioral patterns, consider performing these tasks:
- Evaluate a diverse set of desired queries from different users.
- Identify the objects that might be used in queries. Objects are logical sets of related data, such as a movie in a database of movies.
- Identify the properties and values that compose the object and might be used in queries. Properties are the indexable attributes of the object; they can include primitive values or other objects. For instance, a movie object might have properties such as the movie's title and release date as primitive values. The movie object might also contain other objects, such as cast members, that have their own properties, such as their name or role.
- Identify example valid values for properties. Values are the actual data indexed for a property. For example, one movie's title in your database might be "Raiders of the Lost Ark."
- Determine the sorting and ranking options desired by your users. For example, when querying movies, users might want to sort chronologically and rank by audience rating and do not need to sort alphabetically by title.
- (optional) Consider if one of your properties represents a more specific context in which searches might be executed, such as the users' job role or department, so that autocomplete suggestions can be provided based on the context. For example, for people searching a database of movies, users might only be interested in a certain genre of movies. Users would define what genre they want their searches to return, possibly as part of their user profile. Then, when a user begins to type in a query of movies, only movies in their preferred genre, such as "action movies," are suggested as part of autocomplete suggestions.
- Make a list of these objects, properties, and example values that can be used in searches. (For details on how this list is used, see the Define operator options section.)
Initialize your data source
A data source represents the data from a repository that has been indexed and stored in Google Cloud. For instructions on initializing a data source, refer to Manage third-party data sources.
A user's search results are returned from the data source. When a user clicks on a search result, Cloud Search directs the user to the actual item using the URL supplied in the indexing request.
Define your objects
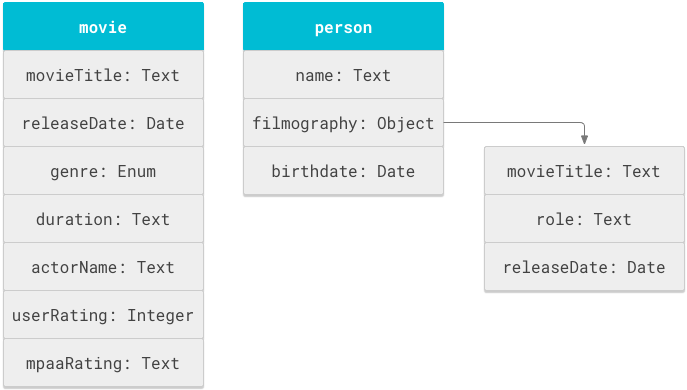
The fundamental unit of data in a schema is the object, also called a "schema object", which is a logical structure of data. In a database of movies, one logical structure of data is "movie." Another object might be "person" to represent the cast and crew involved in the movie.
Every object in a schema has a series of properties or attributes that describe the object, such as the title and duration for a movie, or the name and birthdate for a person. Properties of an object can include primitive values or other objects.
Figure 1 shows the movie and person objects and associated properties.
A Cloud Search schema is
essentially a list of object definition statements defined within the
objectDefinitions tag. The following schema snippet shows
the objectDefinitions statements for the movie and person schema objects.
{
"objectDefinitions": [
{
"name": "movie",
...
},
{
"name": "person",
...
}
]
}
When you define a schema object, you provide a name for the object that must
be unique among all other objects in the schema. Usually you will use a name
value that describes the object, such as movie for a movie object. The schema
service uses the name field as a key identifier for indexable objects. For
further information about the name field, refer to the
Object Definition.
Define object properties
As specified in the reference for
ObjectDefinition,
the object name is followed by a set of
options,
and a list of
propertyDefinitions.
The
options can
further consist of
freshnessOptions
and
displayOptions.
The
freshnessOptions
are used to adjust search ranking based on the freshness of an item. The
displayOptions
are used to define whether specific labels and properties are displayed in
the search results for an object.
The
propertyDefinitions
section is where you define the properties for an object, such as movie title
and release date.
The following snippet shows the movie object with two properties: movieTitle
and releaseDate.
{
"objectDefinitions": [
{
"name": "movie",
"propertyDefinitions": [
{
"name": "movieTitle",
"isReturnable": true,
"isWildcardSearchable": true,
"textPropertyOptions": {
"retrievalImportance": { "importance": "HIGHEST" },
"operatorOptions": {
"operatorName": "title"
}
},
"displayOptions": {
"displayLabel": "Title"
}
},
{
"name": "releaseDate",
"isReturnable": true,
"isSortable": true,
"datePropertyOptions": {
"operatorOptions": {
"operatorName": "released",
"lessThanOperatorName": "releasedbefore",
"greaterThanOperatorName": "releasedafter"
}
},
"displayOptions": {
"displayLabel": "Release date"
}
...
]
}
]
}
The PropertyDefinition consists of the following items:
- a
namestring. - A list of type-agnostic options, such as
isReturnablein the previous snippet. - A type and its associated type-specific options,
such as
textPropertyOptionsandretrievalImportancein the previous snippet. - An
operatorOptionsdescribing how the property is used as a search operator. - One or more
displayOptions, such asdisplayLabelin the previous snippet.
The name of a property must be unique within the containing object,
but the same name can be used in other objects and sub-objects.
In Figure 1, the movie's title and release date have been defined twice:
once in the movie object and again in the filmography sub-object of the
person object. This schema reuses the movieTitle field
so that the schema can support two types of search behaviors:
- Show movie results when users search for the title of a movie.
- Show people results when users search for the title of a movie that an actor played in.
Similarly, the schema reuses the releaseDate field because it has the same
meaning for the two movieTitle fields.
In developing your own schema, consider how your repository might have related fields that contain data that you want to declare more than once in your schema.
Add type-agnostic options
The PropertyDefinition lists general search functionality options common to all properties regardless of data type.
isReturnable- Indicates if the property identifies data that should be returned in search results via the Query API. All of the example movie properties are returnable. Non-returnable properties could be used for searching or ranking results without being returned to the user.isRepeatable- Indicates if multiple values are allowed for the property. For example, a movie only has one release date but can have multiple actors.isSortable- Indicates that the property can be used for sorting. This cannot be true for properties that are repeatable. For example, movie results may be sorted by release date or audience rating.isFacetable- Indicates that the property can be used for generating facets. A facet is used to refine search results whereby the user sees the initial results and then adds criteria, or facets, to further refine those results. This option cannot be true for properties whose type is object andisReturnablemust be true to set this option. Finally, this option is only supported for enum, boolean, and text properties. For example, in our sample schema, we might makegenre,actorName,userRating, andmpaaRatingfacetable to allow them to be used for interactive refinement of search results.isWildcardSearchableindicates that users can perform wildcard search for this property. This option is only available on text properties. How wildcard search works on the text field depends on the value set in the exactMatchWithOperator field. IfexactMatchWithOperatoris set totrue, the text value is tokenized as one atomic value and a wildcard search is performed against it. For example, if the text value isscience-fiction, a wildcard queryscience-*matches it. IfexactMatchWithOperatoris set tofalse, the text value is tokenized and a wildcard search is performed against each token. For example, if the text value is "science-fiction", the wildcard queriessci*orfi*matches the item, butscience-*doesn't match it.
These general search functionality parameters are all boolean values; they
all have a default value of false and must be set to true
to be used.
The following table shows the boolean parameters that are set to true
for all of the properties of the movie object:
| Property | isReturnable |
isRepeatable |
isSortable |
isFacetable |
isWildcardSearchable |
|---|---|---|---|---|---|
movieTitle |
true | true | |||
releaseDate |
true | true | |||
genre |
true | true | true | ||
duration |
true | ||||
actorName |
true | true | true | true | |
userRating |
true | true | |||
mpaaRating |
true | true |
Both genre and actorName have isRepeatable set to true
because a movie may belong in more than one genre and typically has
more than one actor. A property cannot be be sortable if it is repeatable
or contained in a repeatable sub-object.
Define type
The
PropertyDefinition
reference section lists several xxPropertyOptions where xx is a specific type,
such as boolean. To set the data type of the property, you must define
the appropriate data-type object. Defining a data-type object for a property
establishes the data type of that property. For example, defining
textPropertyOptions for the movieTitle property indicates that the movie
title is of type text. The following snippet shows the movieTitle property
with textPropertyOptions setting the data type.
{
"name": "movieTitle",
"isReturnable": true,
"isWildcardSearchable": true,
"textPropertyOptions": {
...
},
...
},
A property may have only one associated data type. For example, in our movie
schema, releaseDate can only be a date (e.g., 2016-01-13) or a string
(e.g., January 13, 2016), but not both.
Here are the data-type objects used to specify the data types for the properties in the sample movie schema:
| Property | Data-type object |
|---|---|
movieTitle |
textPropertyOptions |
releaseDate |
datePropertyOptions |
genre |
enumPropertyOptions |
duration |
textPropertyOptions |
actorName |
textPropertyOptions |
userRating |
integerPropertyOptions |
mpaaRating |
textPropertyOptions |
The data type you choose for property depends on your expected use cases.
In the imagined scenario of this movie schema, users are expected
to want to sort results chronologically, so the releaseDate is a date object.
If, for instance, there was an expected use case of comparing December releases
across the years with January releases, then a string format might be useful.
Configure type-specific options
The
PropertyDefinition
reference section links to options for each type. Most type-specific
options are optional, except the list of possibleValues in the
enumPropertyOptions. Additionally, the orderedRanking option allows you to
rank values relative to each other. The
following snippet shows the movieTitle property with textPropertyOptions
setting the data type and with the retrievalImportance type-specific option.
{
"name": "movieTitle",
"isReturnable": true,
"isWildcardSearchable": true,
"textPropertyOptions": {
"retrievalImportance": { "importance": "HIGHEST" },
...
},
...
}
Here are the additional type-specific options used in the sample schema:
| Property | Type | Type-specific options |
|---|---|---|
movieTitle |
textPropertyOptions |
retrievalImportance |
releaseDate |
datePropertyOptions |
|
genre |
enumPropertyOptions |
|
duration |
textPropertyOptions |
|
actorName |
textPropertyOptions |
|
userRating |
integerPropertyOptions |
orderedRanking, maximumValue |
mpaaRating |
textPropertyOptions |
Define operator options
In addition to type-specific options, each type has a set of optional
operatorOptions These options describe how the property is used as a
search operator. The following snippet shows the movieTitle property with
textPropertyOptions setting the data type and with the
retrievalImportance and operatorOptions type-specific options.
{
"name": "movieTitle",
"isReturnable": true,
"isWildcardSearchable": true,
"textPropertyOptions": {
"retrievalImportance": { "importance": "HIGHEST" },
"operatorOptions": {
"operatorName": "title"
}
},
...
}
Every operatorOptions has an operatorName, such as title for a
movieTitle. The operator name is the search operator for the property. A
search operator is the actual parameter you expect users to use
when narrowing a search. For example, to search movies based on their title, the
user would type title:movieName, where movieName is the name of a movie.
Operator names do not have to be the same as the property's name. Instead, you should use operator names that reflect the most-common words used by users in your organization. For example, if your users prefer the term "name" instead of "title" for a movie title, then the operator name should be set to "name".
You can use the same operator name for multiple properties as long as all
properties resolve to the same type. When using a shared operator name during
a query, all properties using that operator name are retrieved. For example,
suppose the movie object had plotSummary and plotSynopsis
properties and each of these properties had an operatorName of plot. As
long as both of these properties are text (textPropertyOptions), a single
query using the plot search operator retrieves them both.
In addition to operatorName, properties that are sortable can have
lessThanOperatorName and greaterThanOperatorName fields in operatorOptions.
Users can use these options to create queries based on comparisons to a
submitted value.
Finally, the textOperatorOptions has an exactMatchWithOperator field in
operatorOptions. If you
set exactMatchWithOperator to true, the query string must
match the entire property value, not merely be found within the text.
The text value is be treated as one atomic value in operator searches and
facet matches.
For example, consider indexing Book or Movie objects with genre properties.
Genres could include "Science-Fiction", "Science", and "Fiction". With
exactMatchWithOperator set to false or omitted,
searching for a genre or
selecting either the "Science" or "Fiction" facet would also
return results for "Science-Fiction" as the text is tokenized and the
"Science" and "Fiction" tokens exist in "Science-Fiction".
When exactMatchWithOperator is true,
the text is treated as a single token, so neither
"Science" nor "Fiction" matches "Science-Fiction".
(Optional) Add the displayOptions section
There is an optional displayOptions section at the end of any
propertyDefinition section. This section contains one displayLabel string.
The displayLabel is a recommended, user-friendly text label
for the property. If the property is configured for display using
ObjectDisplayOptions,
this label is displayed in front of the property. If the property is configured
for display and displayLabel is not defined, only the property value is
displayed.
The following snippet shows the movieTitle property with a displayLabel
set to 'Title'.
{
"name": "movieTitle",
"isReturnable": true,
"isWildcardSearchable": true,
"textPropertyOptions": {
"retrievalImportance": { "importance": "HIGHEST" },
"operatorOptions": {
"operatorName": "title"
}
},
"displayOptions": {
"displayLabel": "Title"
}
},
Following are the displayLabel values for all of the properties of the movie
object in the sample schema:
| Property | displayLabel |
|---|---|
movieTitle |
Title |
releaseDate |
Release date |
genre |
Genre |
duration |
Run length |
actorName |
Actor |
userRating |
Audience score |
mpaaRating |
MPAA rating |
(Optional) Add suggestionFilteringOperators[] section
There is an optional
suggestionFilteringOperators[]
section at the end of any propertyDefinition section. Use this section to
define a property used to filter autocomplete suggestions. For example, you
might define the operator of genre to filter suggestions based on the user's
preferred movie genre. Then, when the user types their search query, only those
movies matching their preferred genre are displayed as part of autocomplete
suggestions.
Register your schema
To have structured data returned from Cloud Search queries, you must register your schema with the Cloud Search schema service. Registering a schema requires the data source ID you obtained during the Initialize a data source step.
Using the data source ID, issue an UpdateSchema request to register your schema.
As detailed on the UpdateSchema reference page, issue the following HTTP request to register your schema:
PUT https://cloudsearch.googleapis.com/v1/indexing/{name=datasources/*}/schema
The body of your request should contain the following:
{
"validateOnly": // true or false,
"schema": {
// ... Your complete schema object ...
}
}
Use the validateOnly option to test the validity of your schema without
actually registering it.
Index your data
Once your schema is registered, populate the data source using Index calls. Indexing is normally done within your content connector.
Using the movie schema, a REST API indexing request for a single movie would look like this:
{
"name": "datasource/<data_source_id>/items/titanic",
"acl": {
"readers": [
{
"gsuitePrincipal": {
"gsuiteDomain": true
}
}
]
},
"metadata": {
"title": "Titanic",
"sourceRepositoryUrl": "http://www.imdb.com/title/tt2234155/?ref_=nv_sr_1",
"objectType": "movie"
},
"structuredData": {
"object": {
"properties": [
{
"name": "movieTitle",
"textValues": {
"values": [
"Titanic"
]
}
},
{
"name": "releaseDate",
"dateValues": {
"values": [
{
"year": 1997,
"month": 12,
"day": 19
}
]
}
},
{
"name": "actorName",
"textValues": {
"values": [
"Leonardo DiCaprio",
"Kate Winslet",
"Billy Zane"
]
}
},
{
"name": "genre",
"enumValues": {
"values": [
"Drama",
"Action"
]
}
},
{
"name": "userRating",
"integerValues": {
"values": [
8
]
}
},
{
"name": "mpaaRating",
"textValues": {
"values": [
"PG-13"
]
}
},
{
"name": "duration",
"textValues": {
"values": [
"3 h 14 min"
]
}
}
]
}
},
"content": {
"inlineContent": "A seventeen-year-old aristocrat falls in love with a kind but poor artist aboard the luxurious, ill-fated R.M.S. Titanic.",
"contentFormat": "TEXT"
},
"version": "01",
"itemType": "CONTENT_ITEM"
}
Note how the value of movie in the objectType field matches the object
definition name in the schema. By matching these two values, Cloud Search knows
which schema object to use during indexing.
Also note how the indexing of the schema property releaseDate uses
sub-properties of year, month, and day which it inherits because it is
defined as a date data type through using datePropertyOptions to define it.
However, because year, month, and day are not defined in the schema, you
cannot query on one of those properties (e.g., year) individually.
And also note how the repeatable property actorName is indexed by using a list
of values.
Identifying potential indexing problems
The two most common problems relating to schemas and indexing are:
Your indexing request contains an schema object or property name that was not registered with the schema service. This problem causes the property or object to be ignored.
Your indexing request has property with a type value different from the type registered in the schema. This problem causes Cloud Search to return an error at indexing time.
Test your schema with several query types
Before you register your schema for a large production data repository, consider testing with a smaller test data repository. Testing with a smaller test repository allows you to quickly make adjustments to your schema, and delete the indexed data, without impacting a larger index or an existing production index. For a test data repository, create an ACL that authorizes only a test user so that other users won't see this data in Search results.
To create a search interface to validate search queries, refer to The search interface
This section contains several different example queries you might use to test a movie schema.
Test with a generic query
A generic query returns all items in the data source containing a specific string. Using a search interface, you might run generic query against a movie data source by typing in the word "titanic" and pressing Return. All movies with the word "titanic" should be returned in the search results.
Test with an operator
Adding an operator to the query limits the results to the items that match that
operator value. For example, you might want to use the actor operator to find
all movies starring a specific actor. Using a search interface, you can perform
this operator query simply by typing in a operator=value pair, such as
"actor:Zane", and pressing Return. All movies with Zane as an actor
should be returned in the search results.
Tune your schema
After your schema and your data are in use, continue to monitor what is working and not working for your users. You should consider adjusting your schema for the following situations:
- Indexing a field that had not previously been indexed. For example, your users might repeatedly search for movies based on the director name, so you might adjust your schema to support director name as an operator.
- Changing search operator names based on user feedback. Operator names are meant to be user-friendly. If your users consistently "remember" the wrong operator name, you might consider changing it.
Re-indexing after a schema change
Changing any of the following values in your schema does not require you to re-index your data. You can simply submit a new UpdateSchema request and your index will continue to function:
- Operator names.
- Integer minimum and maximum values.
- Integer and enum ordered ranking.
- Freshness options.
- Display options.
For the following changes, previously indexed data will continue to work according to the previously registered schema. However, you must re-index existing entries to see changes based on the updated schema if it has these changes:
- Adding or removing a new property or object
- Changing
isReturnable,isFacetable, orisSortablefromfalsetotrue.
You should set isFacetable or isSortable to be true only if you have a
clear use case and need.
Finally, when you update your schema by marking a property isSuggestable,
you must reindex your data which causes a delay in the use of autocomplete for
that property.
Disallowed property changes
Some schema changes are not allowed, even if you reindex your data, because they will break the index or produce poor or inconsistent search results. These include changes to:
- Property data type.
- Property name.
exactMatchWithOperatorsetting.retrievalImportancesetting.
However, there is a way around this limitation.
Make a complex schema change
To avoid changes that would generate poor search results or a broken search index, Cloud Search prevents certain kinds of changes in UpdateSchema requests after the repository has been indexed. For example, the data type or name of a property cannot be changed after they have been set. These changes cannot be achieved through a simple UpdateSchema request, even if you re-index your data.
In situations where you must make an otherwise disallowed change to your schema, you can often make a series of allowed changes that achieve the same effect. In general, this involves first migrating indexed properties from an older object definition to a newer one and then sending an indexing request that uses only the newer property.
The following steps show how to change the data type or name of a property:
- Add a new property to the object definition in your schema. Use a different name from the property you want to change.
- Issue the UpdateSchema request with the new definition. Remember to send the entire schema, including both the new and old property, in the request.
Backfill the index from the data repository. To backfill the index, send all indexing requests using the new property, but not the old property, since this would lead to double counting query matches.
- During indexing backfill, check for the new property and default to the old property to avoid inconsistent behavior.
- After backfill completes, run test queries to verify.
Delete the old property. Issue another UpdateSchema request without the old property name and discontinue use of the old property name in future indexing requests.
Migrate any usage of the old property to the new property. For example, if you change the property name from creator to author, you must update your query code to use author where it previously referenced creator.
Cloud Search keeps a record of any deleted property or object for 30 days to protect against any re-use that would cause unexpected indexing results. Within that 30 days, you should migrate away from all usage of the deleted object or property, including omitting them from future index requests. This ensures that if you later decide to re-instate that property or object, you can do so in a way that maintains the correctness of your index.
Know size limitations
Cloud Search imposes limits on the size of structured data objects and schemas. These limits are:
- The maximum number of top-level objects is 10 objects.
- The maximum depth of a structured data hierarchy is 10 levels.
- The total number of fields in an object is limited to 1000, which includes the number of primitive fields plus the sum of the number of fields in each nested object.
Next Steps
Here are a few next steps you might take:
Create a search interface to test your schema.
Tune your schema to improve search quality.
Learn how to leverage the
_dictionaryEntryschema to define synonyms for terms commonly used in your company. To use the_dictionaryEntryschema, refer to Define synonyms.Create a connector.