This page describes how to work with the Federated Learning APIs provided by On-Device Personalization to train a model with a federated averaging learning process and fixed Gaussian noise.
Before you begin
Before you begin, complete the following steps on your test device:
Make sure the OnDevicePersonalization module is installed. The module became available as an automatic update in April 2024.
# List the modules installed on the device adb shell pm list packages --apex-only --show-versioncodeEnsure the following module is listed with a version code of 341717000 or higher:
package:com.google.android.ondevicepersonalization versionCode:341717000If that module is not listed, go to Settings > Security & privacy > Updates > Google Play system update to ensure your device is up to date. Select Update as necessary.
Enable all Federated Learning related new features.
# Enable On-Device Personalization apk. adb shell device_config put on_device_personalization global_kill_switch false # Enable On-Device Personalization APIs. adb shell device_config put on_device_personalization enable_ondevicepersonalization_apis true # Enable On-Device Personalization overriding. adb shell device_config put on_device_personalization enable_personalization_status_override true adb shell device_config put on_device_personalization personalization_status_override_value true # Enable Federated Compute apk. adb shell device_config put on_device_personalization federated_compute_kill_switch false
Create a Federated Learning task

The numbers in the diagram are explained in more detail in the following eight steps.
Configure a Federated Compute Server
Federated Learning is a map-reduce that runs on the Federated Compute Server (the reducer) and a set of clients (the mappers). The Federated Compute server maintains each Federated Learning task's running metadata and model information. At a high level:
- A Federated Learning developer creates a new task and uploads both task-running metadata and model information onto the server.
- When a Federated Compute client initiates a new task assignment request to the server, the server checks the eligibility of the task and returns eligible task information.
- Once a Federated Compute client finishes the local computations, it sends these computation results to the server. The server then performs aggregation and noising on these computation results and applies the result to the final model.
To learn more about these concepts, check out:
- Federated Learning: Collaborative Machine Learning without Centralized Training Data
- Towards Federated Learning at Scale: System Design (SysML 2019)
ODP uses an enhanced version of Federated Learning, where calibrated (centralized) noise is applied to the aggregates before applying to the model. The scale of the noise ensures that the aggregates preserve differential privacy.
Step 1. Create a Federated Compute Server
Follow the instructions in the Federated Compute project to set up your own Federated Compute Server.
Step 2. Prepare a Saved FunctionalModel
Prepare a saved 'FunctionalModel' file. You can use 'functional_model_from_keras' to convert a 'Model' to 'FunctionalModel' and use 'save_functional_model' to serialize this 'FunctionalModel' as a 'SavedModel'.
functional_model = tff.learning.models.functional_model_from_keras(keras_model=model)
tff.learning.models.save_functional_model(functional_model, saved_model_path)
Step 3. Create a Federated Compute Server configuration
Prepare a fcp_server_config.json which includes policies, federated learning setup and differential privacy setup. Example:
# Identifies the set of client devices that will participate.
population_name: "my_new_population"
# Options you can choose:
# * TRAINING_ONLY: Only one training task will be generated under this
# population.
# * TRAINING_AND_EVAL: One training task and one evaluation task will be
# generated under this population.
# * EVAL_ONLY: Only one evaluation task will be generated under this
# population.
mode: TRAINING_AND_EVAL
policies {
# Policy for sampling on-device examples. It is checked every time a
# device attempts to start a new training.
min_separation_policy {
# The minimum number of rounds before the same client participated.
minimum_separation: 3
}
# Policy for releasing training results to developers. It is checked
# when uploading a new task to the Federated Compute Server.
model_release_policy {
# Server stops training when number of training rounds reaches this
# number.
num_max_training_rounds: 1000
}
}
# Federated learning setups. They are applied inside Task Builder.
federated_learning {
learning_process {
# Use FED_AVG to build federated learning process. Options you can
# choose:
# * FED_AVG: Federated Averaging algorithm
# (https://arxiv.org/abs/2003.00295)
# * FED_SDG: Federated SGD algorithm
# (https://arxiv.org/abs/1602.05629)
type: FED_AVG
# Optimizer used at client side training. Options you can choose:
# * ADAM
# * SGD
client_optimizer: SGD
# Learning rate used at client side training.
client_learning_rate: 0.01
# Optimizer used at server side training. Options you can choose:
# * ADAM
# * SGD
server_optimizer: ADAM
# Learning rate used at server side training.
sever_learning_rate: 1
runtime_config {
# Number of participating devices for each round of training.
report_goal: 2000
}
# List of metrics to be evaluated by the model during training and
# evaluation. Federated Compute Server provides a list of allowed
# metrics.
metrics {
name: "auc-roc"
}
metrics {
name: "binary_accuracy"
}
}
# Whether or not to generate a corresponding evaluation task under the same
# population. If this field isn't set, only one training task is
# generated under this population.
evaluation {
# The task id under the same population of the source training task that
# this evaluation task evaluates.
source_training_task_id: 1
# Decides how checkpoints from the training task are chosen for
# evaluation.
# * every_k_round: the evaluation task randomly picks one checkpoint
# from the past k rounds of training task checkpoints.
# * every_k_hour: the evaluation task randomly picks one checkpoint
# from the past k hours of training task checkpoints.
checkpoint_selector: "every_1_round"
# The traffic of this evaluation task in this population.
evaluation_traffic: 0.1
# Number of participating devices for each round of evaluation.
report_goal: 200
}
}
# Differential Privacy setups. They are applied inside the Task Builder.
differential_privacy {
# The DP aggregation algorithm you want to use. Options you can choose:
# * FIXED_GAUSSIAN: Federated Learning DP-SGD with fixed clipping norm
# described in "Learning Differentially Private Recurrent
# Language Models" (https://arxiv.org/abs/1710.06963).
# * ADAPTIVE_GAUSSIAN: Federated Learning DP-SGD with quantile-based clip
# norm estimation described in "Differentially Private
# Learning with Adaptive Clipping"
# (https://arxiv.org/abs/1905.03871).
# * TREE: DP-FTRL algorithm described in "Practical and Private (Deep)
# Learning without Sampling or Shuffling"
# (https://arxiv.org/abs/2103.00039).
# * ADADPTIVE_TREE: DP-FTRL with adaptive clipping norm descirbed in
# "Differentially Private Learning with Adaptive Clipping"
# (https://arxiv.org/abs/1905.03871).
type: FIXED_GAUSSIAN
# Noise multiplier for the Gaussian noise.
noise_multiplier: 0.1
# The value of the clipping norm.
clip_norm: 0.1
}
Step 4. Submit the zip configuration to the Federated Compute server.
Submit the zip file and fcp_server_config.json to the Federated Compute server.
task_builder_client --task_builder_server='http://{federated_compute_server_endpoint}' --saved_model='saved_model' --task_config='fcp_server_config.json'
The Federated Compute Server endpoint is the server you set up in step 1.
The LiteRT built-in operator library only supports a limited number of TensorFlow operators (Select TensorFlow operators). The supported operator set may vary across different versions of the OnDevicePersonalization module. To ensure compatibility, an operator verification process is conducted within the task builder during task creation.
The minimum supported OnDevicePersonalization module version will be included in the task metadata. This information can be found in the task builder's info message.
I1023 22:16:53.058027 139653371516736 task_builder_client.py:109] Success! Tasks are built, and artifacts are uploaded to the cloud. I1023 22:16:53.058399 139653371516736 task_builder_client.py:112] applied_algorithms { learning_algo: FED_AVG client_optimizer: SGD server_optimizer: SGD dp_aggregator: FIXED_GAUSSIAN } metric_results { accepted_metrics: "binary_accuracy, binary_crossentropy, recall, precision, auc-roc, auc-pr" } dp_hyperparameters { dp_delta: 0.000001 dp_epsilon: 6.4 noise_multiplier: 1.0 dp_clip_norm: 1.0 num_training_rounds: 10000 } I1023 22:16:53.058594 139653371516736 task_builder_client.py:113] training_task { min_client_version: "341912000" } eval_task { min_client_version: "341812000" }The Federated Compute server will assign this task to all devices equipped with an OnDevicePersonalization module with a version higher than 341812000.
If your model includes operations that are not supported by any OnDevicePersonalization modules, an error message will be generated during task creation.
common.TaskBuilderException: Cannot build the ClientOnlyPlan: Please contact Google to register these ops: {'L2Loss': 'L2LossOp<CPUDevice, float>'} . Stop building remaining artifacts.You can find a detailed list of supported flex ops in GitHub.
Create An Android Federated Compute APK
To create an Android Federated Compute APK, you need to specify the Federated Compute Server URL endpoint in your AndroidManifest.xml, which your Federated Compute Client connects to.
Step 5. Specify the Federated Compute Server URL endpoint
Specify the Federated Compute Server URL endpoint (which you set up in Step 1) in your AndroidManifest.xml, which your Federated Compute Client connects to.
<!-- Contents of AndroidManifest.xml -->
<manifest xmlns:android="http://schemas.android.com/apk/res/android"
package="com.example.odpsample" >
<application android:label="OdpSample">
<!-- XML resource that contains other ODP settings. -->
<property android:name="android.ondevicepersonalization.ON_DEVICE_PERSONALIZATION_CONFIG"
android:resource="@xml/OdpSettings"></property>
<!-- The service that ODP will bind to. -->
<service android:name="com.example.odpsample.SampleService"
android:exported="true" android:isolatedProcess="true" />
</application>
</manifest>
The XML resource file specified in the <property> tag must also declare the service class in a <service> tag, and specify the Federated Compute Server URL endpoint to which the federated compute Client will connect:
<!-- Contents of res/xml/OdpSettings.xml -->
<on-device-personalization>
<!-- Name of the service subclass -->
<service name="com.example.odpsample.SampleService">
<!-- If you want to use federated compute feature to train a model,
specify this tag. -->
<federated-compute-settings url="https://fcpserver.com/" />
</service>
</on-device-personalization>
Step 6. Implement the IsolatedWorker#onTrainingExample API
Implement the On-Device Personalization public API IsolatedWorker#onTrainingExample to generate training data.
Code running in the IsolatedProcess has no direct access to the network, local disks or other services running on the device; however, the following APIs are available:
- 'getRemoteData' - Immutable key-value data downloaded from remote, developer operated backends, if applicable.
- 'getLocalData' - Mutable key-value data locally persisted by developers, if applicable.
- 'UserData' - User data provided by the platform.
- 'getLogReader' - Returns a DAO for the REQUESTS and EVENTS tables.
Example:
@Override public void onTrainingExample(
@NonNull TrainingExampleInput input,
@NonNull Consumer<TrainingExampleOutput> consumer) {
// Check if the incoming training task is the task we want.
if (input.getPopulationName() == "my_new_population") {
TrainingExampleOutput result = new TrainingExampleOutput.Builder():
RequestLogRecord record = this.getLogReader().getRequestLogRecord(1);
int count = 1;
// Iterate logging event table.
for (ContentValues contentValues: record.rows()) {
Features features = Features.newBuilder()
// Retrieve carrier from user info.
.putFeature("carrier", buildFeature(mUserData.getCarrier()))
// Retrieve features from logging info.
.putFeature("int_feature_1",
buildFeature(contentValues.get("int_feature_1")
result.addTrainingExample(
Example.newBuilder()
.setFeatures(features).build().toByteArray())
.addResumptionToken(
String.format("token%d", count).getBytes()))
.build();
count++;
}
consumer.accept(result.build());
}
}
Step 7. Schedule a recurring training task.
On-Device Personalization provides a FederatedComputeScheduler for developers to schedule or cancel federated compute jobs. There are different options to call it through IsolatedWorker, either on a schedule or when an async download completes. Examples of both follow.
Schedule-based Option. Call
FederatedComputeScheduler#scheduleinIsolatedWorker#onExecute.@Override public void onExecute( @NonNull ExecuteInput input, @NonNull Consumer<ExecuteOutput> consumer ) { if (input != null && input.getAppParams() != null && input.getAppParams().getString("schedule_training") != null) { if (input.getAppParams().getString("schedule_training").isEmpty()) { consumer.accept(null); return; } TrainingInterval interval = new TrainingInterval.Builder() .setMinimumInterval(Duration.ofSeconds(10)) .setSchedulingMode(2) .build(); FederatedComputeScheduler.Params params = new FederatedComputeScheduler .Params(interval); FederatedComputeInput fcInput = new FederatedComputeInput.Builder() .setPopulationName( input.getAppParams().getString("schedule_training")).build(); mFCScheduler.schedule(params, fcInput); ExecuteOutput result = new ExecuteOutput.Builder().build(); consumer.accept(result); } }Download Complete Option. Call
FederatedComputeScheduler#scheduleinIsolatedWorker#onDownloadCompletedif scheduling a training task depends on any asynchronous data or processes.
Validation
The following steps describe how to validate if the Federated Learning task is running properly.
Step 8. Validate if the Federated Learning task is running properly.
A new model checkpoint and a new metric file are generated at each round of server side aggregation.
The metrics are in a JSON-formatted file of key-value pairs. The file is generated by the list of Metrics you defined in Step 3. An example of a representative metrics JSON file is as follows:
{"server/client_work/train/binary_accuracy":0.5384615659713745, "server/client_work/train/binary_crossentropy":0.694046676158905, "server/client_work/train/recall":0.20000000298023224, "server/client_work/train/precision":0.3333333432674408, "server/client_work/train/auc-roc":0.3500000238418579, "server/client_work/train/auc-pr":0.44386863708496094, "server/finalizer/update_non_finite":0.0}
You can use something similar to the following script to get model metrics and to monitor training performance:
import collections
import json
import matplotlib.pyplot as plt
from google.cloud import storage
# The population_name you set in fcp_server_config.json in Step 3.
POPULATION_NAME = 'my_new_population'
# The Google Cloud storage you set in Step 1.
GCS_BUCKET_NAME = 'fcp-gcs'
NUM_TRAINING_ROUND = 1000
storage_client = storage.Client()
bucket = storage_client.bucket(GCS_BUCKET_NAME)
metrics = collections.defaultdict(list)
for i in range(NUM_TRAINING_ROUND):
blob = bucket.blob('{}/{}/1/{}/s/0/metrics'.format(GCS_BUCKET_NAME, POPULATION_NAME, i+1))
with blob.open("r") as f:
metric = json.loads(f.read())
for metric_name in metric.keys():
metrics[metric_name].append(metric[metric_name])
for metric_name in metrics:
print(metric_name)
plt.plot(metrics[metric_name])
plt.show()
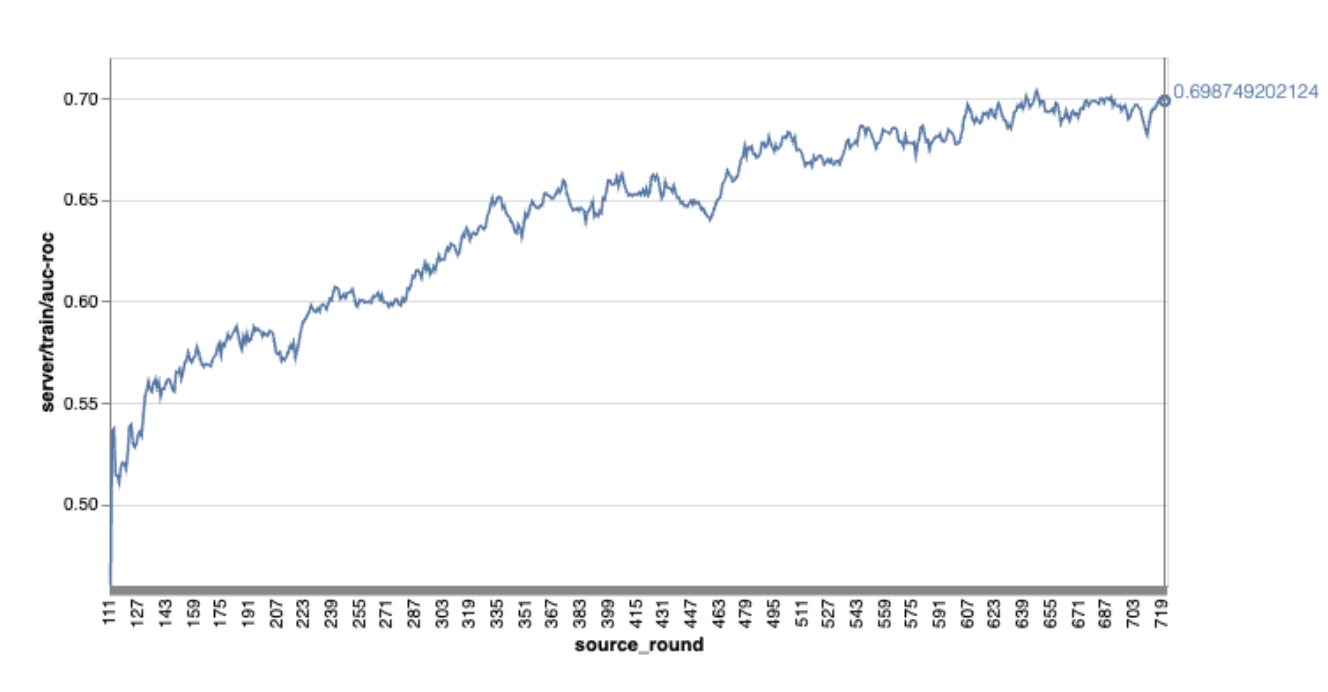
Note that in the preceding example graph:
- The x-axis is the number of round training.
- The y-axis is the value of auc-roc of each round.
Training an Image Classification Model on On-Device Personalization
In this tutorial, the EMNIST dataset is used to demonstrate how to run a federated learning task on ODP.
Step 1. Create a tff.learning.models.FunctionalModel
def get_image_classification_input_spec():
return (
tf.TensorSpec([None, 28, 28, 1], tf.float32),
tf.TensorSpec([None, 1], tf.int64),
)
def create_and_save_image_classification_functional_model(
model_path: str,
) -> None:
keras_model = emnist_models.create_original_fedavg_cnn_model(
only_digits=True
)
functional_model = tff.learning.models.functional_model_from_keras(
keras_model=keras_model,
input_spec=get_image_classification_input_spec(),
loss_fn=tf.keras.losses.SparseCategoricalCrossentropy(),
)
tff.learning.models.save_functional_model(functional_model, model_path)
- You can find the emnist keras model details in emnist_models.
- TfLite doesn't have good support for tf.sparse.SparseTensor or tf.RaggedTensor yet. Try to use tf.Tensor as much as possible when building the model.
- The ODP Task Builder will overwrite all metrics when building the learning process, there is no need to specify any metrics. That topic will be covered more in Step 2. Create the task builder configuration.
Two types of model inputs are supported:
Type 1. A tuple(features_tensor, label_tensor).
- When creating the model, the input_spec looks like:
def get_input_spec(): return ( tf.TensorSpec([None, 28, 28, 1], tf.float32), tf.TensorSpec([None, 1], tf.int64), )- Pair the preceding with the following implementation of the ODP public API IsolatedWorker#onTrainingExamples to generate training data on device:
return tf.train.Example( features=tf.train.Features( feature={ 'x': tf.train.Feature( float_list=tf.train.FloatList(value=[1.0] * 784) ), 'y': tf.train.Feature( int64_list=tf.train.Int64List( value=[1] ) ), } ) ).SerializeToString()Type 2. A
Tuple(Dict[feature_name, feature_tensor], label_tensor)- When creating the model, the input_spec looks like:
def get_input_spec() -> ( Tuple[collections.OrderedDict[str, tf.TensorSpec], tf.TensorSpec] ): return ( collections.OrderedDict( [('feature-1', tf.TensorSpec([None, 1], tf.float32)), ('feature-2', tf.TensorSpec([None, 1], tf.float32))] ), tf.TensorSpec([None, 1], tf.int64), )- Pair the preceding with the following implementation of the ODP public API IsolatedWorker#onTrainingExamples to generate training data:
return tf.train.Example( features=tf.train.Features( feature={ 'feature-1': tf.train.Feature( float_list=tf.train.FloatList(value=[1.0]) ), 'feature-2': tf.train.Feature( float_list=tf.train.FloatList(value=[2.0]) ), 'my_label': tf.train.Feature( int64_list=tf.train.Int64List( value=[1] ) ), } ) ).SerializeToString()- Don't forget to register the label_name in the task builder configuration.
mode: TRAINING_AND_EVAL # Task execution mode population_name: "my_example_model" label_name: "my_label"
ODP handles DP automatically when building the learning process. So there is no need to add any noise when creating the functional model.
The output of this saved functional model should look like the sample in our GitHub repository.
Step 2. Create the task builder configuration
You can find samples of task builder configuration in our GitHub repository.
Training and evaluation Metrics
Given that metrics may leak user data, the Task Builder will have a list of metrics the learning process can generate and release. You can find the full list in our GitHub repository.
Here is a sample metric list when creating a new task builder configuration:
federated_learning { learning_process { metrics { name: "binary_accuracy" } metrics { name: "binary_crossentropy" } metrics { name: "recall" } metrics { name: "precision" } metrics { name: "auc-roc" } metrics { name: "auc-pr" } } }
If the metrics you are interested in are not in the present list, contact us.
DP configurations
There are a few DP related configurations that need specifying:
policies { min_separation_policy { minimum_separation: 1 } model_release_policy { num_max_training_rounds: 1000 dp_target_epsilon: 10 dp_delta: 0.000001 } } differential_privacy { type: FIXED_GAUSSIAN clip_norm: 0.1 noise_multiplier: 0.1 }- Either
dp_target_epsilonornoise_mulitipileris present to pass validation: (noise_to_epsilonepislon_to_noise). - You can find these default settings in our GitHub repository.
- Either
Step 3. Upload the saved model and task builder configuration to any developer's cloud storage
Remember to update artifact_building fields when uploading the task builder configuration.
Step 4. (optional) Test artifact building without creating a new task
cd ${odp_fcp_github_repo}/python
bazel run //python/taskbuilder:task_builder_client -- --saved_model=${path_of_cloud_storage}/mnist_model/ --task_config=${path_of_cloud_storage}/mnist_cnn_task_config_build_artifact_only.pbtxt --build_artifact_only=true --task_builder_server=${task_builder_server_endpoint}
The sample model is validated through both the flex ops check and dp check; you can add skip_flex_ops_check and skip_dp_check to bypass during validation (this model can't be deployed to the current version of ODP client due to a few missing flex ops).
cd ${odp_fcp_github_repo}/python
bazel run //python/taskbuilder:task_builder_client -- --saved_model=${path_of_cloud_storage}/mnist_model/ --task_config=${path_of_cloud_storage}/mnist_cnn_task_config_build_artifact_only.pbtxt --build_artifact_only=true --task_builder_server=${task_builder_server_endpoint} --skip_flex_ops_check=True --skip_dp_check=True
flex_ops_check: the TensorFlow Lite built-in operator library only supports a limited number of TensorFlow operators (TensorFlow Lite and TensorFlow operator compatibility). All incompatible tensorflow ops need to be installed using the flex delegate (Android.bp). If a model contains unsupported ops, contact us to register them:
Cannot build the ClientOnlyPlan: Please contact Google to register these ops: {...}The best way to debug a task builder is to start one locally:
# Starts a server at localhost:5000 bazel run //python/taskbuilder:task_builder # Links to a server at localhost:5000 by removing task_builder_server flag bazel run //python/taskbuilder:task_builder_client -- --saved_model=${path_of_cloud_storage}/mnist_model/ --task_config=${path_of_cloud_storage}/mnist_cnn_task_config_build_artifact_only.pbtxt --build_artifact_only=true --skip_flex_ops_check=True --skip_dp_check=True
You can find the resultant artifacts at the cloud storage specified in the configuration. It should be something that looks like the example in our GitHub repository.
Step 5. Build artifacts and create a new pair of training and eval tasks on the FCP server.
Remove the build_artifact_only flag and the built artifacts will be uploaded to the FCP server. You should check that a pair of training and eval tasks are created successfully
cd ${odp_fcp_github_repo}/python
bazel run //python/taskbuilder:task_builder_client -- --saved_model=${path_of_cloud_storage}/mnist_model/ --task_config=${path_of_cloud_storage}/mnist_cnn_task_config.pbtxt --task_builder_server=${task_builder_server_endpoint}
Step 6. Get FCP client side ready
- Implement the ODP public API
IsolatedWorker#onTrainingExamplesto generate training data. - Call
FederatedComputeScheduler#schedule. - Find a few examples in our Android source repository.
Step 7. Monitoring
Server metrics
Find setup instructions in our GitHub repository.
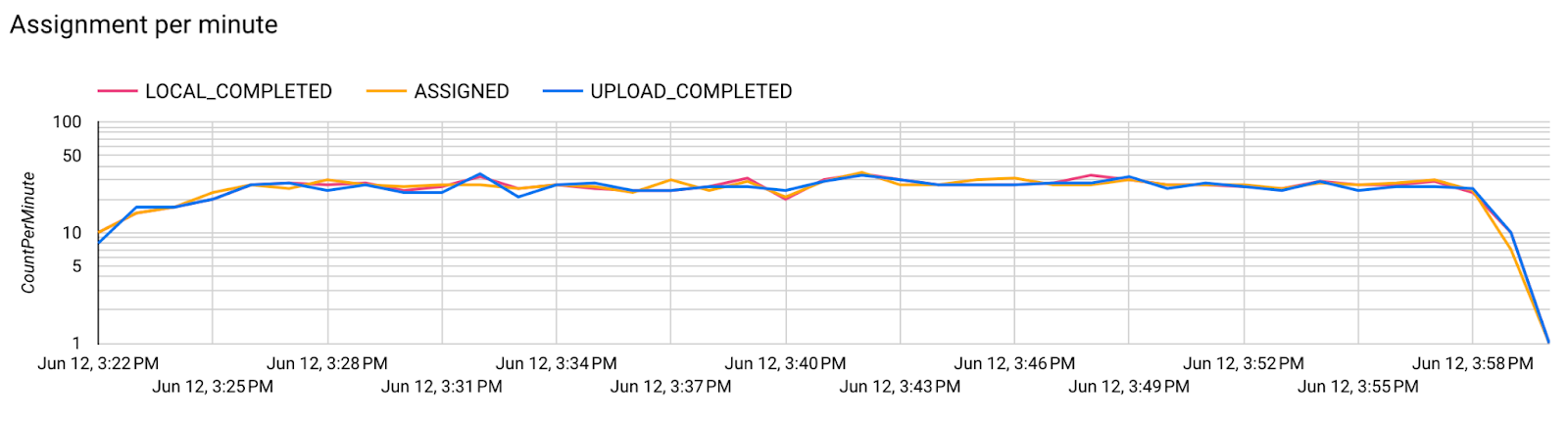
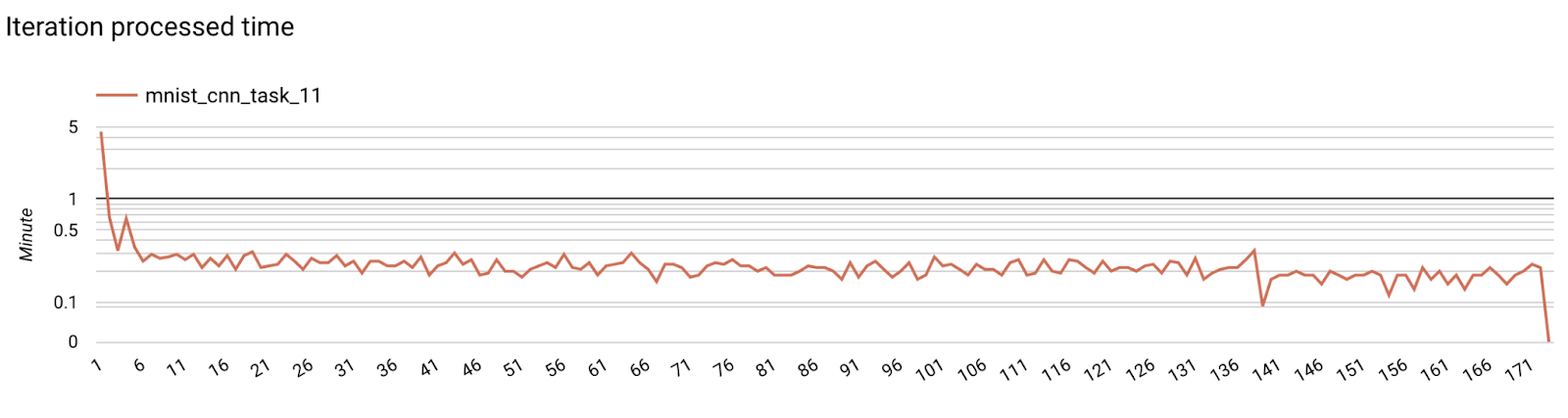
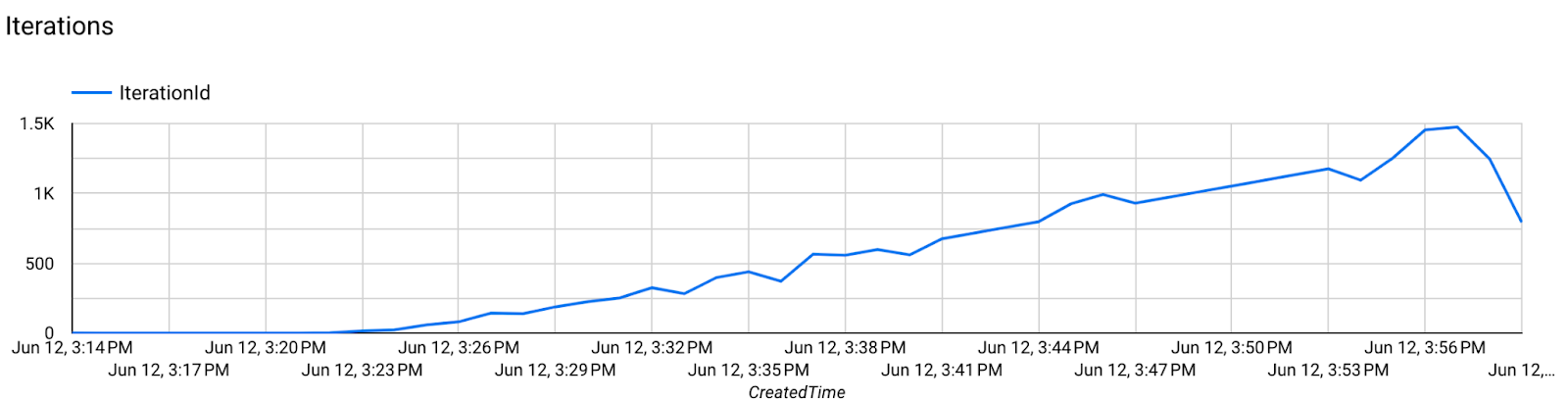
- Model Metrics
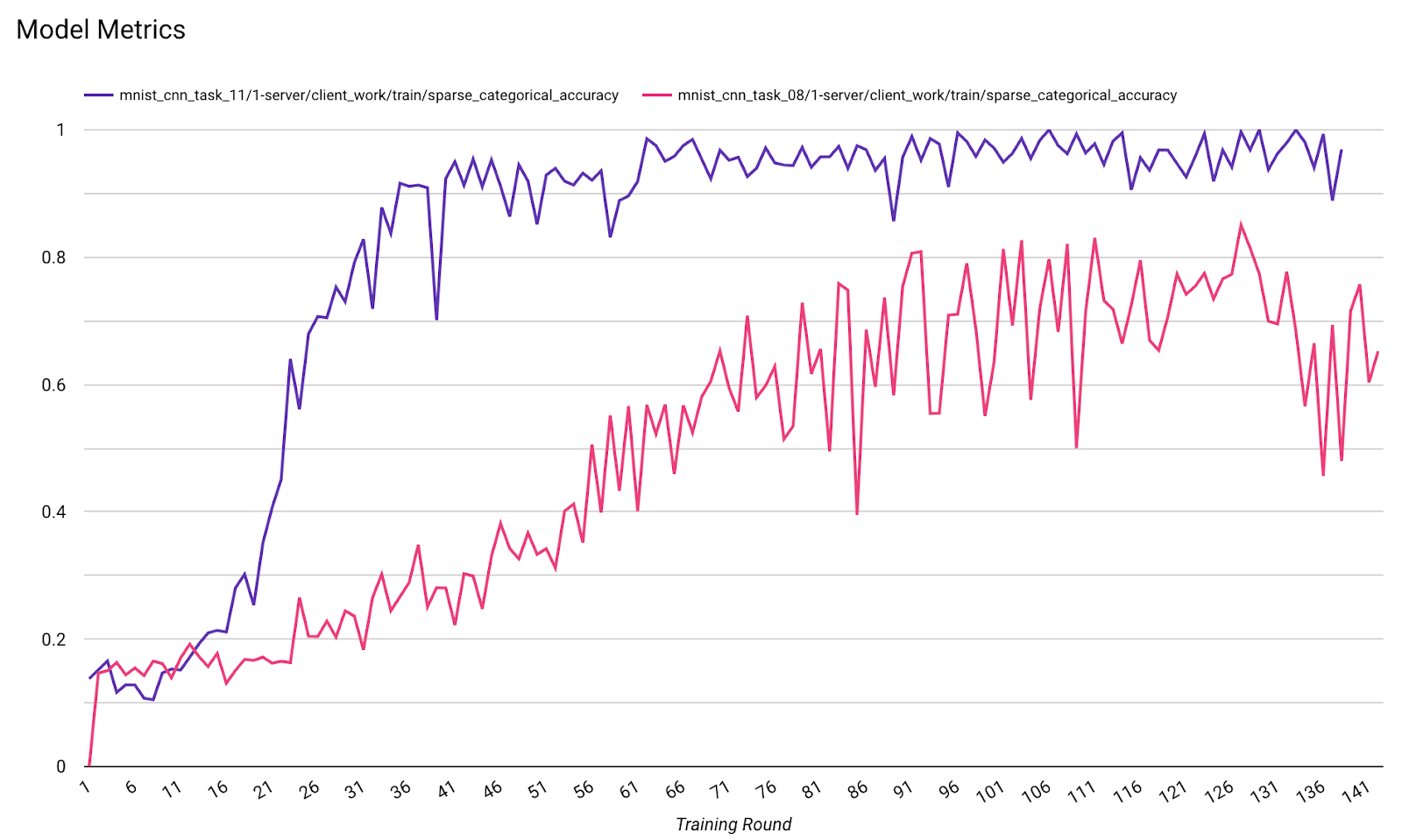
It's possible to compare metrics from different runs in one diagram. For example:
- The purple line is with
noise_multiplier0.1 - The pink line is with
noise_multipiler0.3