Stay organized with collections
Save and categorize content based on your preferences.
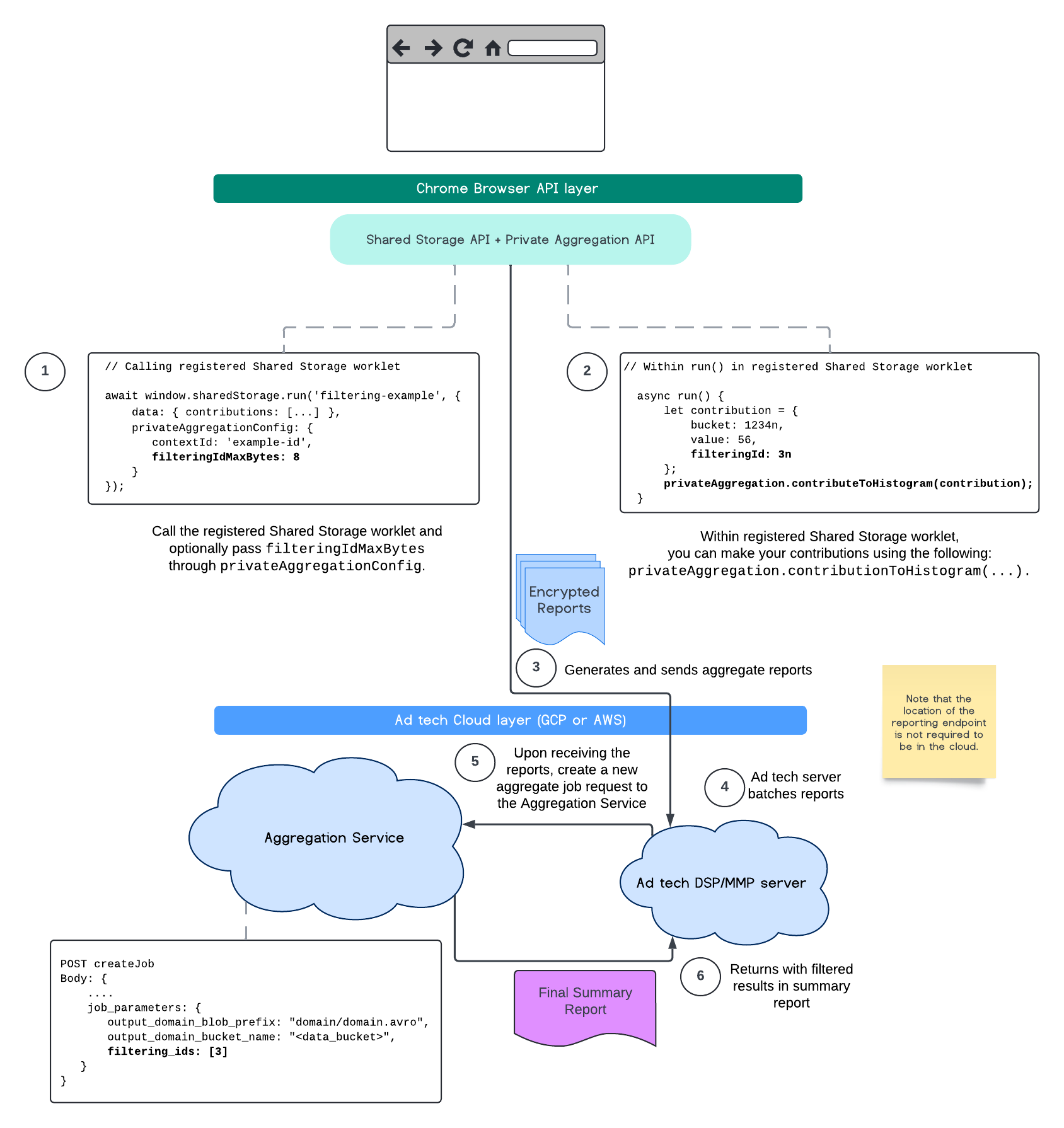
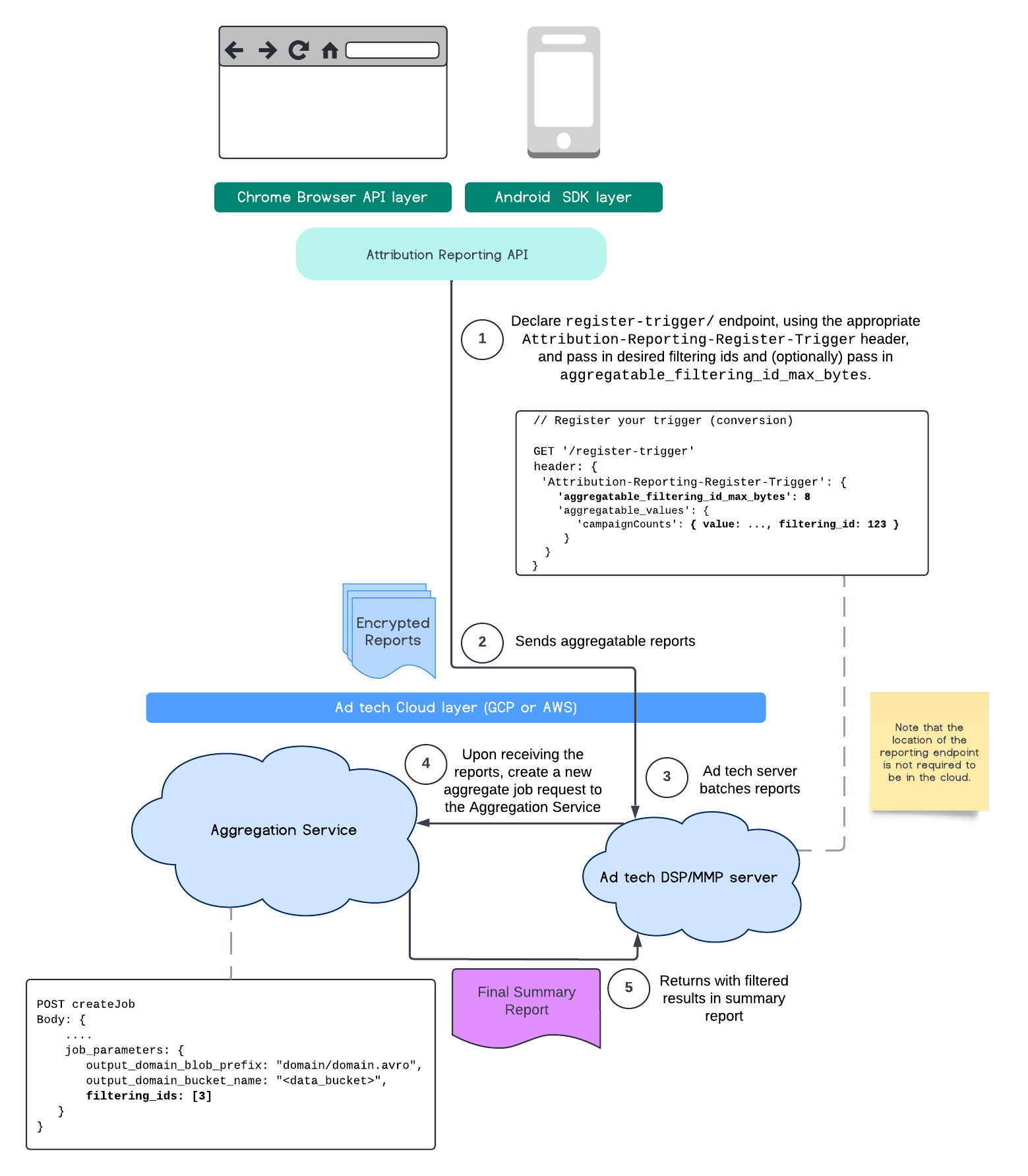
At this time, with the Aggregation Service, you may now process certain measurements at different cadences by leveraging filtering IDs.
Filtering IDs can now be passed on job creation within your Aggregation Service like so:
In order to use this filtering implementation, it's recommended to start from the measurement client APIs (Attribution Reporting API or Private Aggregation API) and pass in your filtering IDs. These will be passed to your deployed Aggregation Service, so that your final summary report returns back with expected filtered results.
If you are concerned with how this will affect your budget, your aggregate report account budget will only be consumed for filtering IDs that are specified in your job_parameters for reports. This way, you will be able to re-run jobs for the same reports specifying different filtering IDs without running into budget exhaustion errors.
[[["Easy to understand","easyToUnderstand","thumb-up"],["Solved my problem","solvedMyProblem","thumb-up"],["Other","otherUp","thumb-up"]],[["Missing the information I need","missingTheInformationINeed","thumb-down"],["Too complicated / too many steps","tooComplicatedTooManySteps","thumb-down"],["Out of date","outOfDate","thumb-down"],["Samples / code issue","samplesCodeIssue","thumb-down"],["Other","otherDown","thumb-down"]],["Last updated 2024-12-05 UTC."],[[["The Aggregation Service now allows processing certain measurements at different cadences using filtering IDs."],["Filtering IDs are specified during job creation to control which data is included in the aggregated reports."],["Budgets are only consumed for filtering IDs specified in the job parameters, enabling flexible report generation without budget exhaustion."],["This functionality is integrated with the Attribution Reporting API and Private Aggregation API for flexible data processing."],["Detailed documentation and explainers are available for further information on implementation and usage."]]],["The Aggregation Service now supports processing measurements at different cadences using filtering IDs. These IDs, passed during job creation, specify which data to include. Filtering IDs are initiated via the Attribution Reporting or Private Aggregation APIs. Budget is only consumed for specified filtering IDs, allowing job reruns with different IDs. This process is facilitated through the Private Aggregation and Shared Storage APIs, as well as with the Attribution Reporting API, flowing through to the Aggregation Service.\n"]]