Aggregation Service generates summary reports of detailed conversion data and reach measurements from raw aggregatable reports. To keep user data private and secure, Aggregation Service uses a framework that supports differential privacy (DP) to quantify and limit the amount of information these reports reveal about individual users.
This guide discusses tools and strategies for creating aggregatable reports that help keep data about individual users secure:
- Create summary reports with added noise
- Set a contribution budget
- Strategies for report batching
- Handle duplicate reports in batches
- Handle reports with a common shared ID
- Use pre-declared aggregation keys
Summary reports with added noise
When you batch aggregatable reports, Aggregation Service creates a summary report. This summary report is an aggregate of all the contributions of all the predefined domain keys, with added statistical noise.
The noise added to the reports doesn't depend on the number of reports aggregated, individual report values, or aggregated report values. Noise is drawn from a discrete version of the Laplace distribution, and is scaled to the contribution budget (L1 sensitivity) that is enforced by the client dependent on the corresponding measurement API and the privacy parameter epsilon.
To learn more about noise and its implications for report data, see Understanding noise in summary reports.
Contribution budget
To control the sensitivity of a summary report, the number of contributions passed in a call is tied to a specific contribution bounding limit, also known as the contribution budget. The contribution budget varies depending on whether you're using the Attribution Reporting API or the Private Aggregation API.
To learn more about how to set contribution budgets for each API, see the following API documentation sections:
- Attribution Reporting API contribution bounding and budgeting
- Private Aggregation API contribution limits
- Private Aggregation API contribution bounding and budgeting
Strategies for report batching
When you batch aggregatable reports, it's important to optimize batching strategies so that privacy limits aren't exceeded. Two important concepts for batching reports correctly are the "no duplicates" rule and the idea of disjoint batches.
"No duplicates" rule
Aggregation Service enforces a "no duplicates" rule. This rule states that an aggregatable report, which is uniquely identified by report_id, can only appear once in a single batch. If an aggregatable report appears more than once per batch, the first report is included in the aggregation, subsequent reports with the same report_id are discarded, and the batch completes successfully.
The rule also states that the same shared ID can't appear in more than one batch. If a Shared ID has already been included in a previous successful batch, a later batch that also included the same shared ID would fail.
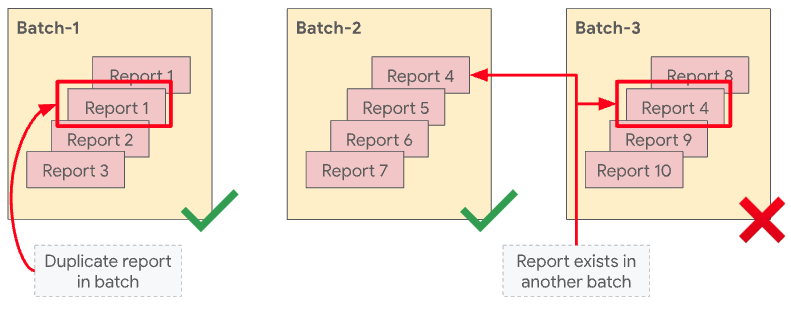
Without the "no duplicates" rule, an attacker could gain insight to the contents of a specific batch by manipulating the contents of the batches through including duplicate copies of a report in a single batch or multiple batches.
To learn more about enforcing the "no duplicates" rule within a batch of reports or across multiple batches, see Duplicate reports within batches.
Disjoint batches
To avoid situations in which there is overlap between batches, Aggregation Service enforces disjoint batches. This means that two or more batches can't contain reports that share a common shared ID. A shared ID is a combination of data collected from the shared_info field of an aggregatable report, along with the filtering ID from the job request. If no filtering ID is specified, a default of 0 is used.
In the following shared_info field example, you can see the API, attribution_destination (for Attribution Reporting), reporting_origin, scheduled_report_time, source_registration_time (for Attribution Reporting), and version. These fields, except for the report_id, along with filtering ID from the job request, contribute to the shared ID.
"shared_info": {
"API": "attribution-reporting",
"attribution_destination": "https://privacy-sandbox-demos-shop.dev",
"report_id": "5b052748-f5fb-4f14-b291-de03484ed59e",
"reporting_origin": "https://privacy-sandbox-demos-dsp.dev",
"scheduled_report_time": "1707786751",
"source_registration_time": "0",
"version": "0.1"
}
Since source_registration_time is truncated by the day and scheduled_report_time is truncated by the hour, there are reports that have the same shared ID. In this example, Report1 and Report2 have shared info fields. Both reports have the same API, version, attribution_destination, reporting_origin, and source_registration_time. Since report_id isn't part of the shared ID, you can ignore this difference.
In the following examples for Report1 and Report2, the scheduled_report_time value is the same.
Report1 shared info:
"shared_info": {
"API": "attribution-reporting",
"attribution_destination": "https://shop.dev",
"report_id": "5b052748-...",
"reporting_origin": "https://dsp.dev",
"scheduled_report_time": "1708376890",
"source_registration_time": "0",
"version": "0.1"
}
Report2 shared info:
"shared_info": {
"API": "attribution-reporting",
"attribution_destination": "https://shop.dev",
"report_id": "5b052748-...",
"reporting_origin": "https://dsp.dev",
"scheduled_report_time": "1708376890",
"source_registration_time": "0",
"version": "0.1"
}
The scheduled report times are "February 19, 2024 9:08:10 PM" for Report1 and "February 19, 2024 9:55:10 PM" for Report2. Because the value for the scheduled_report_time field is truncated to the hour, both reports have 1708376890 (the encoded value for "February 19, 2024 9 PM") as the value for the scheduled_report_time field.
With all the other fields and the filtering ID the same, both reports have the same shared ID. And since both reports have the same shared ID, they must both be included in the same batch.
If Report1 was batched in a previously successful batch and Report2 gets processed in a subsequent batch, the batch with Report2 fails with a PRIVACY_BUDGET_EXHAUSTED error. If this happens, remove the reports with the shared ID that have been successfully batched in prior batches and try again. For more information about this error, see Error codes and mitigations for Aggregation Service.
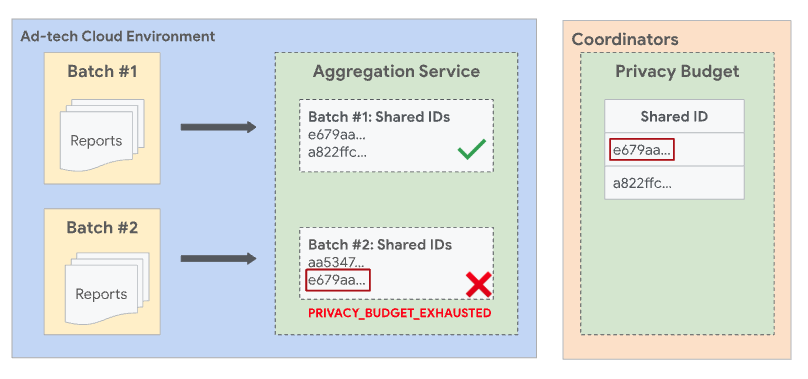
Pre-declared aggregation keys
When you submit a batch to Aggregation Service, it must include both the aggregatable reports that are received from the reporting origin and the output domain file. The output domain contains the keys, or buckets, that are retrieved from the aggregatable reports.
From a privacy standpoint, noise is added to all keys pre-declared in the output domain, even when no real report matches a particular key. Specifying the output domain protects against an attack where the presence of a key in the output reveals something about a single user or event. For example, if you only showed a campaign to one user, receiving a key in the output reveals that the user later converted, even with noise added. By specifying this domain first, you can be sure that it doesn't reveal anything about the user contributions.
You can declare these 128-bit keys in either the Attribution Reporting API or the Private Aggregation API and use them to encode dimensions you want to track.
Only pre-declared keys are considered for aggregation and included in the summary report. The aggregated values of the buckets in the summary report have statistical noise added, which is reflected in the created summary report.
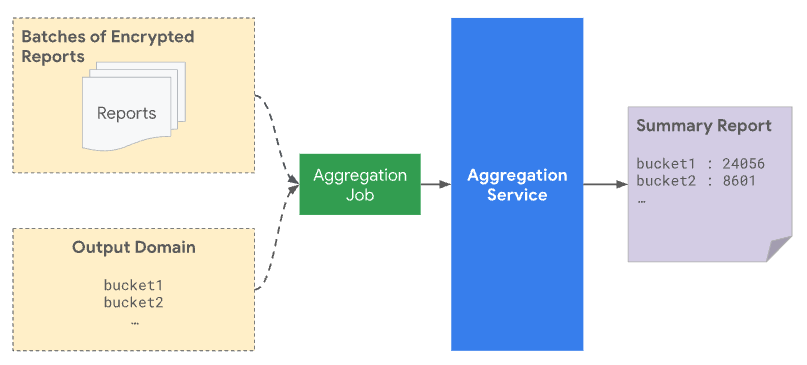
If an aggregation key is included in the output domain file but isn't located in a batch report, even if the aggregated value is zero, the final summary report will likely be non-zero because of the added noise to preserve privacy.