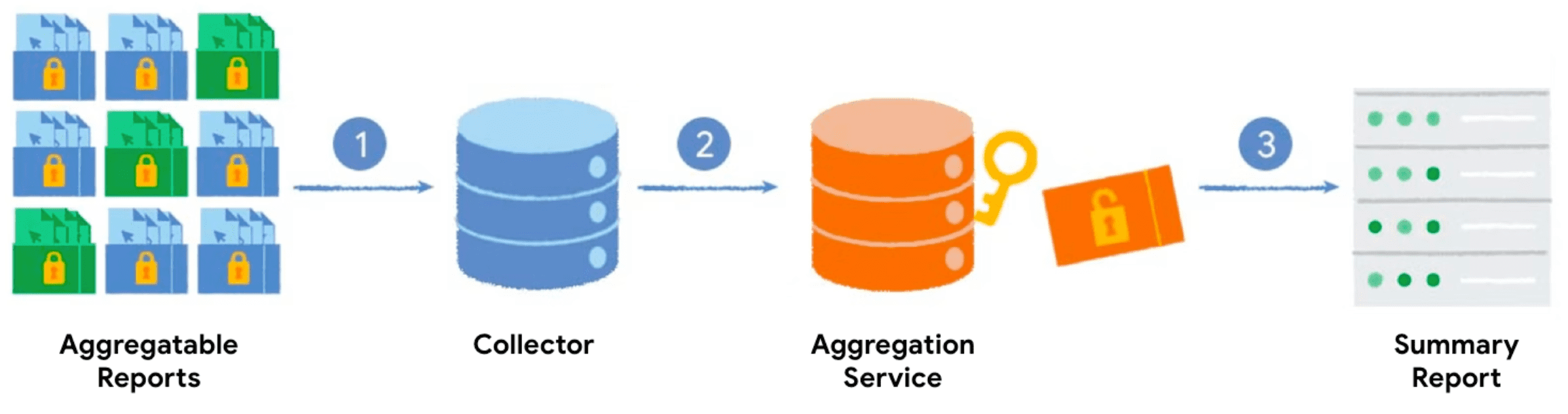
Private Aggregation
To provide critical features that the web relies on, the Private Aggregation API has been built for aggregating and reporting on cross-site data in a privacy-preserving manner. With Private Aggregation, generate aggregate data reports using data from Protected Audience and cross-site data from Shared Storage.
Use cases with Shared Storage

Measure unique reach
Use Private Aggregation to produce a summary report of the first time users saw your content without any duplication of data.
Measure user demographics
Use Shared Storage to record available user demographic data.
Measure K+ frequency
Use Shared Storage to build reports of unique users that have seen a piece of content at least K number of times.
Engage and share feedback
Your feedback is key to improving Private Aggregation. By sharing your insights, you contribute to the development of a privacy-respecting approach to interest-based advertising.
Reach out to us
Developer support
Create a new issue to ask questions about the implementation currently available in Chrome.
GitHub
Read the explainer, and raise questions and follow discussion about the design of the Topics API.
Announcements
Join the Shared Storage API group and the Protected Audience API group to receive latest updates on Private Aggregation.