Thursday, September 01, 2011
Our mission is to organize the world's information and make it universally accessible and useful. During this ambitious quest, we sometimes encounter non-HTML files such as PDFs, spreadsheets, and presentations. Our algorithms don't let different filetypes slow them down; we work hard to extract the relevant content and to index it appropriately for our search results. But how do we actually index these filetypes, and—since they often differ so much from standard HTML — what guidelines apply to these files? What if a webmaster doesn't want us to index them?
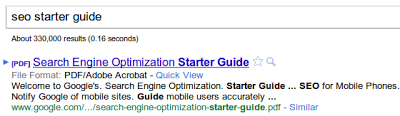
Google first started indexing PDF files in 2001 and currently has hundreds of millions of PDF files indexed. We've collected the most often-asked questions about PDF indexing; here are the answers:
Q: Can Google index any type of PDF file?
A: Generally we can index textual content (written in any language) from PDF files that use
various kinds of character encodings, provided they're not password protected or encrypted. If the
text is embedded as images, we may process the images with
OCR
algorithms to extract the text. The general rule of the thumb is that if you can copy and paste
the text from a PDF document into a standard text document, we should be able to index that text.
Q: What happens with the images in PDF files?
A: Currently the images are not indexed. In order for us to index your images, you should create
HTML pages for them. To increase the likelihood of us returning your images in our search results,
please read the
Google Images best practices.
Q: How are links treated in PDF documents?
A: Generally links in PDF files are treated similarly to links in HTML: they can pass PageRank
and other indexing signals, and we may follow them after we have crawled the PDF file. It's
currently not possible to use
nofollow
links within a PDF document.
Q: How can I prevent my PDF files from appearing in search results; or if they already do, how
can I remove them?
A: The simplest way to prevent PDF documents from appearing in search results is to add an
X-Robots-Tag: noindex in the HTTP header used to serve the file. If they're already
indexed, they'll drop out over time if you use the X-Robot-Tag with the
noindex rule. For faster removals, you can use the
URL removal tool
in Google Webmaster Tools.
Q: Can PDF files rank highly in the search results?
A: Sure! They'll generally rank similarly to other webpages. For example, at the time of this
post,
mortgage market review,
irs form 2011, or
paracetamol expert report
all return PDF documents that manage to rank highly in our search results, thanks to their content
and the way they're embedded and linked from other webpages.
Q: Is it considered duplicate content if I have a copy of my pages in both HTML and PDF?
A: Whenever possible, we recommend serving a single copy of your content. If this isn't possible,
make sure you indicate your preferred version by, for example, including the preferred URL in your
sitemap or by specifying the canonical version in the HTML or in the
HTTP headers
of the PDF resource. For more tips, read our Help Center article about
canonicalization.
Q: How can I influence the title shown in search results for my PDF document?
A: We use two main elements to determine the title shown: the title metadata within the file, and
the anchor text of links pointing to the PDF file. To give our algorithms a strong signal about
the proper title to use, we recommend updating both.
If you want to learn more, watch Matt Cutt's video about PDF files' optimization for search, and visit our Help Center for information about the content types we're able to index. If you have feedback or suggestions, please let us know in the Webmaster Help Forum.