Tuesday, May 27, 2014
The Fetch as Google feature in Webmaster Tools provides webmasters with the results of Googlebot attempting to fetch their pages. The server headers and HTML shown are useful to diagnose technical problems and hacking side-effects, but sometimes make double-checking the response hard: Help! What do all of these codes mean? Is this really the same page as I see it in my browser? Where shall we have lunch? We can't help with that last one, but for the rest, we've recently expanded this tool to also show how Googlebot would be able to render the page.
Viewing the rendered page
In order to render the page, Googlebot will try to find all the external files involved, and fetch them as well. Those files frequently include images, CSS and JavaScript files, as well as other files that might be indirectly embedded through the CSS or JavaScript. These are then used to render a preview image that shows Googlebot's view of the page.
You can find the Fetch as Google feature in the Crawl section of Google Webmaster Tools. After submitting a URL with "Fetch and render," wait for it to be processed (this might take a moment for some pages). Once it's ready, just click on the response row to see the results.
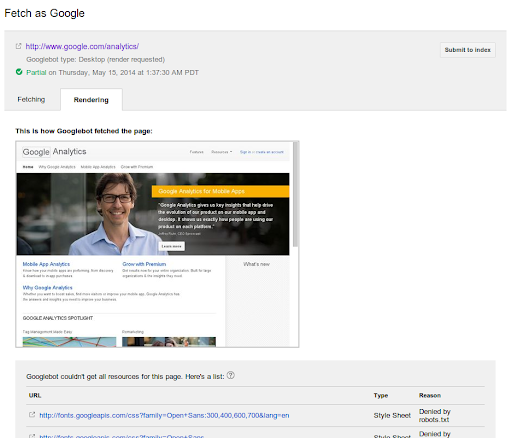
Handling resources blocked by robots.txt
Googlebot follows the robots.txt rules for all files that it fetches. If you are disallowing crawling of some of these files (or if they are embedded from a third-party server that's disallowing Googlebot's crawling of them), we won't be able to show them to you in the rendered view. Similarly, if the server fails to respond or returns errors, then we won't be able to use those either (you can find similar issues in the Crawl Errors section of Webmaster Tools). If we run across either of these issues, we'll show them below the preview image.
We recommend making sure Googlebot can access any embedded resource that meaningfully contributes to your site's visible content, or to its layout. That will make Fetch as Google easier for you to use, and will make it possible for Googlebot to find and index that content as well. Some types of content—such as social media buttons, fonts or website-analytics scripts—tend not to meaningfully contribute to the visible content or layout, and can be left disallowed from crawling. For more information, please see our previous blog post on how Google is working to understand the web better.
We hope this update makes it easier for you to diagnose these kinds of issues, and to discover content that's accidentally blocked from crawling. If you have any comments or questions, let us know here or drop by in the webmaster help forum.